기본개념
1. System (SW) Life Cycle 의 개념
1.
요구사항 분석 단계 (Requirements)
2.
시스템 분석 단계 (Analysis)
a.
상향식 설계 (Bottom-up)
i.
세부 기능의 구현을 초기에 강조
ii.
결과 프로그램 = 세부 기능들의 조합
iii.
단점 : 주어진 문제의 고유 특성을 고려하지 않는 설계가 될 위험이 있다
b.
하향식 설계 (Top-down)
i.
프로그램을 관리 가능한 세그먼트들로 분할
ii.
단점 : 도미노 효과 발생 가능
3.
설계 단계 (Design)
a.
데이터와 연산의 관점에서 접근
i.
데이터 관점 : 추상적 데이터 타입
ii.
연산의 관점 : 알고리즘
b.
프로그래밍 언어에 독립적
4.
구현 단계 (Refinement and Coding)
a.
주요 고려 사항 : 성능 (Performance)
5.
검증 단계 (Verification)
a.
정확성 증명 (Correctness Proof)
b.
검사 (Testing)
•
양질의 테스트 데이터는 실행 코드의 모든 부분을 검사
•
프로그램의 실행 시간도 측정
c.
오류 제거 (Error Removal)
좋은 프로그램이란?
•
문서화
•
전체 프로그램이 기능적으로 깔끔하게 분리
•
각 부분은 인자 전달 (메시지 전달, 함수 호출 등)로 상호 동작
알고리즘 명세
알고리즘?
→ 어떤 일을 수행하기 위한 유한 개의 명령어들의 나열
모든 알고리즘들이 만족해야 할 조건들
•
입력 (Input)
◦
0 혹은 그 이상의 입력이 존재
•
출력 (Output)
◦
적어도 하나 이상의 결과물이 출력
•
명확성 (Definiteness)
◦
알고리즘을 구성하는 명령어들의 의미는 명확해야함, 모호X
•
유한성 (Finiteness)
◦
한정된 수의 명령어 수행후, 반드시 종료되어야 함
•
실행 가능성 (Effectiveness)
알고리즘 예) Selection Sorting
→ SWAP 함수
// 함수
void swap(int *x, int *y) {
int temp = *x;
*x = *y;
*y = temp;
}
// 매크로
#define SWAP(x, y, t) ((t)=(x), (x)=(y), (y)=(t))
C
복사
→ Selection Sorting 알고리즘
void sort(int list[], int n) {
int i, j, min, temp;
for (i = 0; i < n-1; i++) {
min = i;
for (j = i + 1; j < n; j++)
if (list[j] < list[min])
min = j;
SWAP(list[i], list[min], temp);
}
}
C
복사

데이터 수가 n개일 때, 비교 연산의 수
알고리즘 예2) 이진 검색 (Binary Search)
1.
left = 0, rigth = n-1, middle = (left+right) / 2 로 설정
2.
list[middle] 과 key를 비교
→ Compare 구현 방법
// 매크로
#define compare(x, y) (((x)<(y)) ? -1 : ((x)==(y)) ? 0 : 1)
// 함수
int compare(int x, int y) {
if (x < y) return -1;
else if (x == y) return 0;
else return 1;
}
C
복사
→ Binary Search 알고리즘
int binsearch(int list[], int key, int left, int right) {
int middle;
while (left <= right) {
middle = (left + right) / 2;
switch (compare(list[middle], key)) {
case -1:
left = middle + 1;
break;
case 0:
return middle;
case 1:
right = middle - 1;
}
}
return -1;
}
C
복사

재귀 알고리즘 (Recursive Algorithms)
•
재귀 알고리즘의 특징
◦
문제 자체가 재귀적일 경우 적함 (ex. 피보나치 수열)
◦
이해하기가 용이하나, 비효율적일 수 있음
◦
ex) 이진검색(Binary Search), 순열(Permutations)
•
재귀 알고리즘을 작성하는 방법
◦
재귀 호출을 종료하는 경계 조건을 설정
◦
각 단계마다 경계 조건에 접근하도록 알고리즘의 재귀 호출
재귀알고리즘) 순열 (Permutations)
•
{a, b, c}에 대한 순열의 집합 =
◦
{(a, b, c), (a, c, b), (b, a, c), (b, a, c), (c, a, b), (c, b, a)}
순열을 출력하는 재귀함수
void perm(char *list, int i, int n) {
// list[i]에서 list[n]까지의 원소로 구성된 모든 순열 출력
// {a, b, c, d}의 경우 초기 호출 = perm(list, 0, 3)
int temp;
if (i == n) // 단 하나의 순열만 존재한다면 그냥 출력
for (int j = 0; j <= n; j++)
printf("%c", list[j]);
printf("\n");
}
else { // 하나 이상의 순열 존재, 재귀적으로 출력
for (int j = i; j <= n; j++) {
SWAP(list[i], list[j], temp);
perm(list, i+1, n);
SWAP(list[i], list[j], temp);
}
}
}
C
복사

데이터 추상화 (Data Abstraction)
C언어에서 데이터 타입
기본형 : char, int, float, double
확장형 : short, long, unsigned
그룹화 : array, struct, union
포인터
데이터 타입의 정의
•
데이터 객체의 모음, 그 데이터 객체에 적용 가능한 연산들의 집합
추상적 데이터 타입 (Abstract Data Type)
Abstract Data Type (ADT)
•
데이터 객체 및 연산의 명세와 데이터 객체의 내부 표현 양식/연산의 구현 내용을 분리
◦
Ada package, C++ class
ADT에서 연산의 명세
•
구성 요소
◦
함수 이름, 인자들의 타입, 결과들의 타입
•
함수의 호출 방법 및 결과물이 무엇인지를 설명
•
함수의 내부 동작과정 및 구현 방법은 은폐
•
Information Hiding
연산 명세에서 내부 함수들의 종류
•
생성자 (Creator / Constructor)
◦
데이터 객체의 새로운 인스턴스 생성
•
Transformer
◦
기존 인스턴스를 이용하여 새로운 인스턴스를 생성
•
관찰자 (Observer / Reporter)
◦
인스턴스에 대한 정보를 출력

성능 분석 (Performance Analysis)
프로그램의 평가 기준
•
주어진 문제를 해결
•
정확성 (Correctness)
→ 필수적인 요소
•
문서화 (Documentation)
•
모듈화 (Modulariztion)
•
가독성 (Readability)
→ 좋은 프로그래밍 습관
•
공간 효율성 (Space efficiency)
•
시간 효율성 (Time efficiency)
→ 성능과 관련
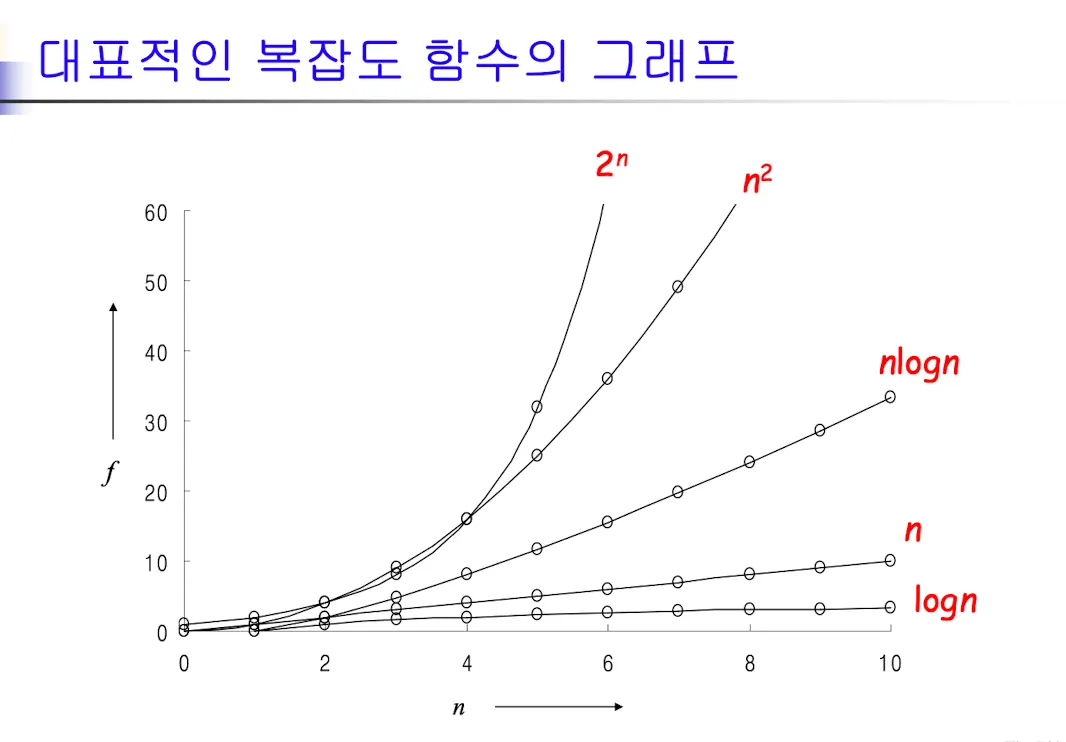
복잡도 (Complexity)
•
공간 복잡도 : 프로그램 실행에 소요되는 메모리
•
시간 복잡도 : 프로그램의 실행 시간
공간 복잡도 (Space Complexity)
•
고정적인 공간 요구사항
◦
입력과 출력 크기에 무관한 공간들
•
가변적인 공간 요구사항 :
◦
I의 수나 크기, 그리고 I/O의 횟수 등에 따라 가변적인 공간
•
프로그램 P의 전체 공간 요구
ex) 단순 산술 함수
float abc(float a, float b, float c) {
return a + b + b * c + (a + b+ c)/(a+b) + 4.0;
}
C
복사
ex) 배열에 저장된 원소들의 합 : Program 1.11
float sum (float list[], int n) {
float tempsum = 0;
for (int i = 0; i < n; i++)
tempsum += list[i];
return tempsum;
}
// S_{sum}(I) = 0
float rsum (float list[], int n) {
if (n) return rsum(list, n-1) + list[n-1];
return 0;
}
// S_{rsum}(I) = (n+1)(float* + int)
C
복사
시간 복잡도 (Time Complexity)
= 컴파일 시간 + 실행 시간
•
컴파일 시간은 고정 & 한번만 필요
•
질문 : 를 어떻게 계산할까?
◦
는 컴파일러 option과 하드웨어 사양에 따라 가변
◦
프로그램 단계 수(Program Step)을 활용
Program Step
•
실행 시간이 프로그램의 특성과는 무관한 프로그램의 문법적인 혹은 논리적인 단위
•
Program Step의 계산 : count를 이용
→ Count 이용 예
float sum(float list[], int n) {
float tempsum = 0; count++; // for '=assignment'
for (int i = 0; i < n; i++) {
count++; // for the 'for loop'
count++; // for 'assignment'
}
count++; // last execution of for
count++; // for 'return'
return tempsum;
C
복사
float rsum(float list[], int n) {
count++; // for if conditional
if (n) {
count++; // for return and rsum invocation
return rsum(list, n-1) + list[n-1];
}
count++;
return list[0];
}
C
복사
→ 행렬 더하기
void add(int a[][MAX_SIZE}, int b[][MAX_SIZE], int c[][MAX_SIZE], int rows, int cols) {
for (int i = 0; i < rows; i++) {
count++;
for (int j = 0 ; j < cols; j++) {
count++;
c[i][j] = a[i][j] + b[i][j];
count++;
}
count++;
}
count++;
}
C
복사
Step Count Table



근사 표현 (O, , )
•
정확한 step count를 계산하는 것은 쉽지 않다
•
Program Step의 정의 자체가 정확하지 않다
•
100n + 10과 30n + 30의 비교
접근 방법
•
이라고 가정
•
n이 충분히 클 경우, 임의의 에 대해,
근사 표현 f(n) = O(g(n))
Theorem
만약 , 그땐
Proof
for all n ≥ 1
근사 표현 f(n) = (g(n))
f(n) = (g(n))
•
≤ ≤ , ≥
ex)
3n + 2 = (n)
→ 3n ≤ 3n+2 ≤ 4n, n ≥ 2
Magic Square 마방진

→ Magic Square 알고리즘
#include <stdio.h>
#define MAX_SIZE 15
void main(void) {
int square[MAX_SIZE][MAX_SIZE];
int i, j, row, column;
int size;
int count;
printf("Enter the size of the square: ");
scanf("%d", &size);
if (size < 1 || size > MAX_SIZE+1) {
printf("Error! Size is out of range\n");
}
if (!(size % 2)) {
printf("Error! Size is even\n");
return;
}
for (i = 0; i < size; i++)
for (j = 0; j < size; j++)
square[i][j] = 0;
square[0][size/2] = 1;
i = 0; // i는 현재 행 번호
j = size / 2 // j는 현재 열 번호
for (count = 2; count <= size*size; count++) {
row = (i-1 < 0) ? (size-1) : (i-1); // 위쪽 행
column = (j-1 < 0) ? (size-1) : (j-1); // 왼쪽 행
if (square[row][column] != 0) {
i = (++i) % size; // 못갈 경우 아래로 이동
}
else { // 갈 수 있을 경우, i와 j를 대각선 위로,
i = row;
j = column;
}
square[i][j] = count; // 변경된 위치에 다음 수 추가
}
// 생성된 magic square를 출력
printf("Magic Square of size %d : \n\n", size);
for (i = 0; i < size; i++) {
for (j = 0; j < size; j++) {
printf("%5d", square[i][j]);
printf("\n");
}
printf("\n\n");
}
C
복사
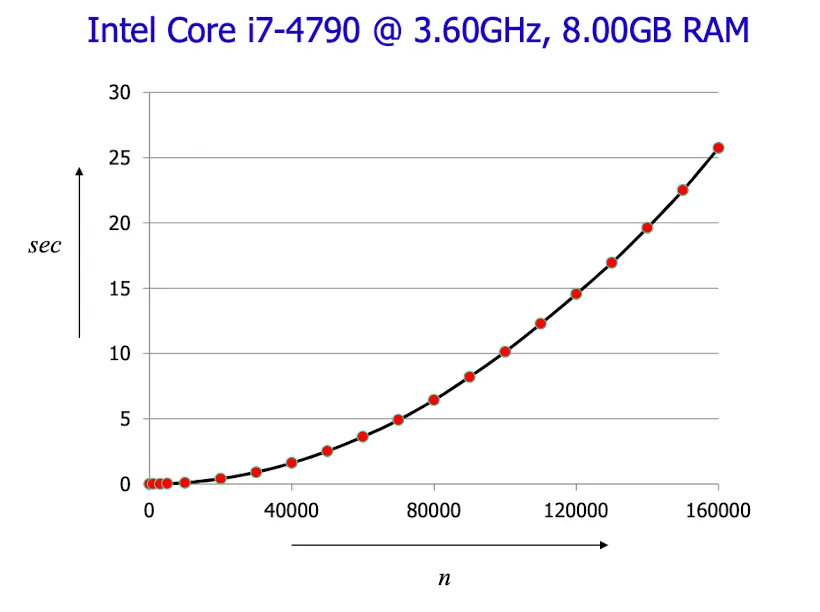
성능 측정 (Performance Measurement)
Selection Sort 시간 측정
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX_SIZE 1601
#define ITERATIONS 42
#define SWAP(x, y, t) ((t)=(x), (x)=(y), (y)=(t))
void sort(int list[], int n) {
int i, j, min, temp;
for (i = 0; i < n-1; i++) {
min = i;
for (j = i + 1; j < n; j++)
if (list[j] < list[min])
min = j;
SWAP(list[i], list[min], temp);
}
}
int main(void) {
int position;
int list[MAX_SIZE];
int sizelist[] = {0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 200, 300, 400,
500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600
,1700, 1800, 1900, 2000, 2100, 2200, 2300, 2400, 2500, 2600, 2700, 2800,
2900, 3000};
clock_t start, stop;
double duration;
printf(" n time\n");
for (int i = 0; i < ITERATIONS; i++) {
for (int j = 0; j < sizelist[i]; j++)
list[j] = sizelist[i]-j;
start = clock(); // 시작 시간 측정
sort(list, sizelist[i]); // sort 함수 호출
stop = clock(); // 종료 시간 측정
// CLOCKS_PER_SEC = 초당 클럭의 수, Macro: 1000
duration = ((double)(stop-start)) / CLOCKS_PER_SEC;
printf("%6d %.2f\n", sizelist[i], duration);
}
}
C
복사